pinterest images scrape(selenium实现) |
您所在的位置:网站首页 › pinterest 下载图片 › pinterest images scrape(selenium实现) |
pinterest images scrape(selenium实现)
|
今天记录海外图片素材网站Pinterest的图片爬取 初步分析:网站是动态渲染网站,每往下滑动,刷新出来新的页面;通过观察刷新后的网页,初步定位每页的请求url是https://www.pinterest.com/resource/BaseSearchResource/get/,可以看到这是一个POST请求,
确定思路:决定用selenium之后,思路如下:先通过selenium打开网页,网页链接为:‘https://www.pinterest.com/search/pins/?q=关键词’,然后通过元素定位到图片链接;最重要的,调用driver.execute_script()方法来实现页面滑动(这里需要提前调试获取每次滑动高度的最佳值),然后再次定位新页面的元素,找到图片链接;对于重复的进行去重;直到滑到底部之后停止滑动,将定位的所有图片链接保存至.txt文档,以便后续下载图片。 完整代码和注释如下: 以下是获取图片链接并保存到本地: from selenium import webdriver from selenium.webdriver import Chrome from selenium.webdriver import ChromeOptions from selenium.webdriver.common.action_chains import ActionChains from selenium.webdriver.common.by import By import json import time cr_options = ChromeOptions() cr_options.add_argument("--start-maximized") #将浏览器最大化 # Input keywords queries = [ # 想要搜索分类的关键词 # '頭貼 卡通', '动物 头像', # '可愛頭貼', # '文字 头像', # '人物 头像', # 'ins风 头像', # '油画 头像', # '摄影 风景', ] driver = Chrome('chromedriver.exe', options=cr_options) print('Size: ' + str(driver.get_window_size())) # 这里输出浏览器尺寸是为了后面调试每次滑动的最佳高度 original_urls = set() # 将图片的原始链接存储在集合内,自动去重 lasts = [] for query in queries: base_url = f'https://www.pinterest.com/search/pins/?q={query}' driver.get(base_url) time.sleep(2) for i in range(30): # 这里为了保证滑到底部,所以循环次数写到了30,但其实可能不需要30次 print('i----------',i) # 输出i来记录滑动了几次(翻了几页) if i |
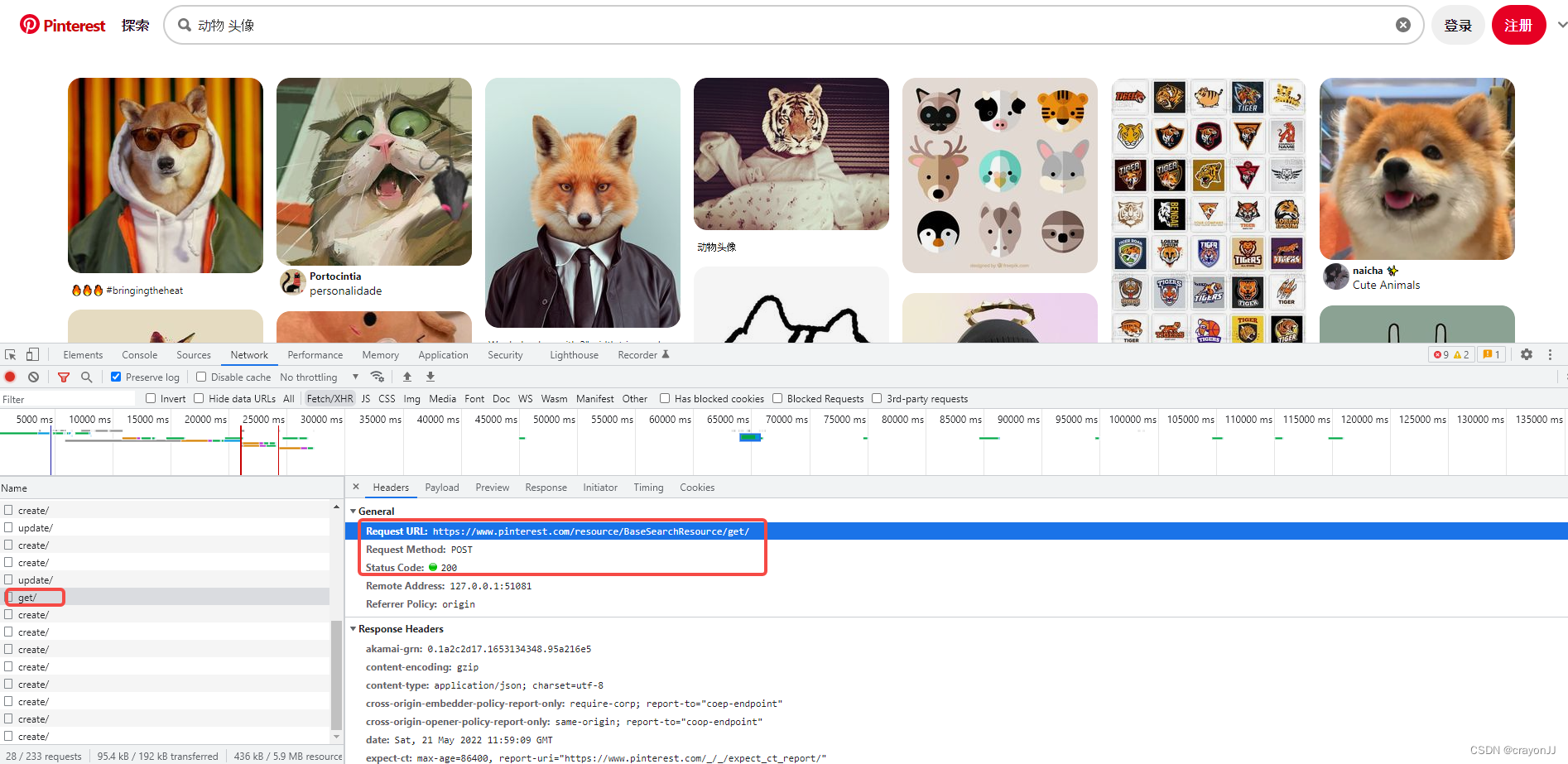 之后分析Preview和Response可以确定该url里面的确有我们要的数据:
之后分析Preview和Response可以确定该url里面的确有我们要的数据: 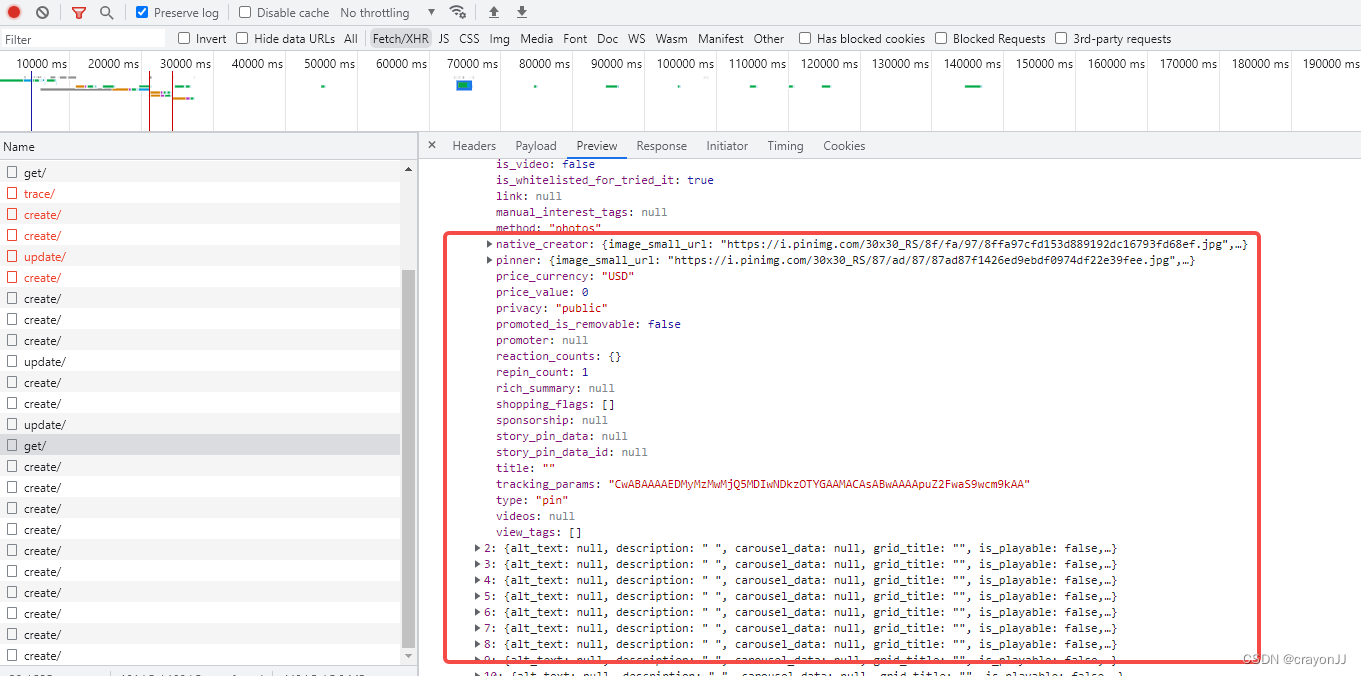 但是该POST请求有两个加密参数:source_url和data;经对比后,发现每页数据的source_url是相同的,data的属性里面,除了bookmarks不同,其他属性也全部相同。
但是该POST请求有两个加密参数:source_url和data;经对比后,发现每页数据的source_url是相同的,data的属性里面,除了bookmarks不同,其他属性也全部相同。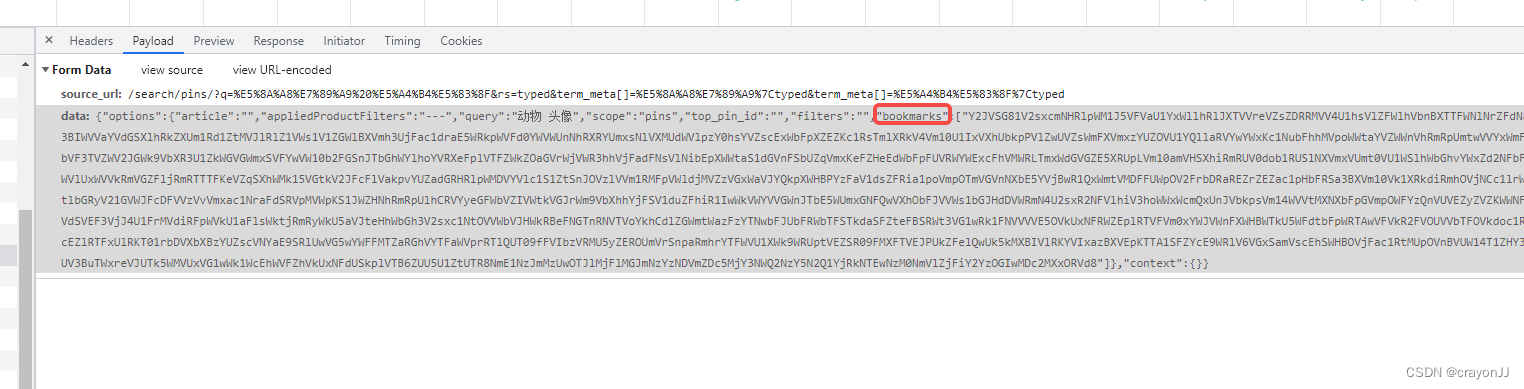 初步思路是通过js逆向解析出bookmarks,然后得到每一页直接的规律;但是!!!该属性逆向分析起来实在很难,对于不会JS的人,断点打着打着就不知道自己的目标变量跑哪里去了。最后放弃逆向解析的方法,改用selenium实现。
初步思路是通过js逆向解析出bookmarks,然后得到每一页直接的规律;但是!!!该属性逆向分析起来实在很难,对于不会JS的人,断点打着打着就不知道自己的目标变量跑哪里去了。最后放弃逆向解析的方法,改用selenium实现。【本文地址】
今日新闻 |
推荐新闻 |